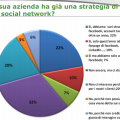
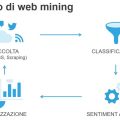
Qualche settimana fa ho partecipato ad un faccia a faccia con Nando Pagnoncelli (IPSOS) che ci ha permesso di confrontarci sulle tecniche di sondaggio delle opinioni. L’idea era di mettere in evidenza che le survey tradizionali e il web mining non sono metodologie contrapposte di rilevazione, ma possono essere complementari, ognuna con i suoi vantaggi e svantaggi.
L’analisi delle conversazioni online permette un’osservazione delle opinioni spontanee, in tempo reale, rapida, continuativa e a prezzi ragionevoli. Di converso non può contare sulla rappresentatività campionaria, pregio delle ricerche di mercato classiche, e fa fatica a interpretare espressioni ironiche. In questi ultimi anni a questi problemi, se ne sono aggiunti altri che hanno ridimensionato una metodologia ancora utile.
Quando ho iniziato a esplorare la rete con l’aiuto della tecnologia (si veda la prima mappatura dei blog e di Twitter) c’era una libertà di analisi che oggi manca. Il rischio attuale è l’impossibilità di osservare nella loro interezza i fenomeni che animano la rete e dunque una parte consistente dell’umanità. Un duro colpo per la ricerca a scopo commerciale, ma ancor di più per quella accademica.
Fino a qualche anno fa era possibile analizzare le conversazioni online anche attraverso strumenti gratuitamente disponibili. Sicuramente erano limitati, ma davano un’idea di cosa stesse accadendo e delle reti che si andavano formando attorno a specifici argomenti. Le aziende, invece, potevano pagare e ricorrere a strumenti più sofisticati per le esigenze di marketing più disparate.
Poi sono accaduti alcuni fatti che hanno trasformato radicalmente lo scenario: l’espansione del web, le limitazioni dei social media, l’arricchimento dei formati.
L’espansione del web. Fino a quando la rete è stata una galassia fatta di pagine web, di blog, di forum, di newsgroup e del pianeta Twitter, fare data mining è stato alla portata di tutti. Bastava avere qualche rudimento di Python per fare scraping di informazioni e procedere alle successive classificazioni. Poi con la crescita ed il successo di Facebook le cose si sono complicate. Siccome lì le conversazioni sono private o semi-private perché avvengono sul profilo/bacheca dell’utente, non è possibile rilevarle. L’unico posto pubblico sono le pagine business dove, però, avvengono soltanto conversazioni relative al brand o al personaggio pubblico titolare della pagina. Ma per fare l’analisi bisognerebbe avere la lista degli indirizzi di tutte le pagine e scaricarne il contenuto a determinati intervalli. Attività improba e costosa.
Le limitazioni dei social media. Gradualmente a partire dal 2012 abbiamo assistito anche ad un processo di limitazione delle possibilità di analisi da parte dei social media. Ha iniziato Twitter quando, realizzando che i suoi dati avevano un valore per aziende e società di web monitoring, nel 2017 ha iniziato ad offrire l’accesso alle sue API più pregiate dietro corrispettivo. Ora quindi chi costruisce software di monitoraggio compra le API, tutti gli altri sfruttano quelle gratuite, ma con delle limitazioni (numero tweet, frequenza di chiamate, ecc.).
Poi nel 2018 è esploso lo scandalo che ha coinvolto Cambridge Analytica e il suo utilizzo spregiudicato delle API di Facebook. Le conseguenze sono state devastanti per gli sviluppatori e le aziende che le utilizzavano correttamente per attività di monitoraggio. Oggi l’analisi della parte pubblica di Facebook e di Instagram è possibile con i tool di listening disponibili sul mercato, ma solo attraverso l’utilizzo di specifiche API (spesso l’accesso viene fatto fare con le credenziali dell’utente che quindi sfrutta il suo token personale). Questo consente alle piattaforme di controllare chi accede e limitare l’uso che fa dei dati degli utenti, nel rispetto della privacy.
Le attività di scraping sono espressamente vietate da tutti i social media perché non sarebbero tracciabili e potrebbero consentire la raccolta massiva di informazioni per scopi non legali.
L’arricchimento dei formati. In questi anni i confini del web non si sono solo ampliati a nuovi luoghi di aggregazione e scambio, ma hanno anche accolto il fiorire di nuovi formati di contenuti. Quattro di questi hanno reso difficile il monitoraggio dei messaggi:
- le immagini: tipicamente gli strumenti di monitoraggio non analizzano il contenuto delle immagini, perché è un’attività molto laboriosa. A volte si limitano a riconoscere il logo del brand cliente ai fini di individuarne l’uso scorretto o le contraffazioni. Ma, generalmente, raccolgono solo il testo della descrizione;
- i video: l’allargamento della banda e la disponibilità di strumenti per produrre video ha spinto i social media a dare ampio spazio a questa tipologia di contenuti. Il problema è che i tool di monitoraggio analizzano soltanto le descrizioni, non l’audio dei video, quindi la comprensione rimane limitata (spesso i video di TikTok hanno descrizioni brevi o criptiche, mentre quelle di YouTube possono essere lunghe ma poco specifiche e fuorvianti quando ripropongono sempre le stesse informazioni su attrezzature usate e offerte commerciali);
- l’audio: il proliferare dei podcast e l’attenzione dei social ai contenuti audio sta escludendo anche queste informazioni dalle possibilità di monitoraggio perché i software attuali non hanno queste capacità di analisi della voce;
- i contenuti effimeri: il formato Storie, adottato dalle piattaforme più popolari, ha posto nuovi problemi di analisi. Esse possono essere catturate attraverso le API (quindi avendo un token valido), ma non possono essere conservate perché hanno una durata limitata alle 24 ore. Quindi i tool di monitoraggio, per motivi di privacy, possono tener traccia delle performance generate dalla Storia, ma non mostrarla.
Queste limitazioni si traducono in un’impossibilità di rilevare per tempo fenomeni interessanti o critici che nascono in luoghi chiusi o impermeabili agli strumenti di ricerca. Ma la cosa peggiore è la tendenza a scambiare pochi tweet per fenomeni rilevanti. Questo succede perché gli strumenti di monitoraggio rilevano facilmente quello che si scrive su Twitter e meno facilmente tutto ciò che avviene sulle piattaforme più popolose.
Naturalmente le aziende hanno ancora necessità di strumenti di monitoraggio per capire bisogni e interessi del mercato, purché abbiano analisti e data scientist che li sappiano utilizzare avendo ben presente i loro limiti e andando oltre il mero dato quantitativo.