C’è una nuova buzzword che sta galvanizzando l’attenzione della Silicon Valley “Generative AI”. Col termine Intelligenza Artificiale generativa ci si riferisce all’utilizzo di tecniche di machine learning e deep learning per generare contenuti nuovi sulla base di dati pregressi. In particolare, parliamo dell’utilizzo di modelli linguistici di grandi dimensioni (Large Language Models) che permettono di ottenere testi, immagini, video, codice inedito a partire da un input testuale.
Le fasi dell’IA Generativa
Si tratta di un campo non nuovo, ma che ha subìto un’accelerazione rapida in quest’ultimo anno. Il perché è presto detto: oggi abbiamo più dati che in passato, più potenza computazione e dei migliori algoritmi generativi. E siamo solo all’inizio: Sequoia Capital prevede un impatto economico di trilioni di dollari nei prossimi anni.
Fino al 2015 per permettere ad una macchina di comprendere il linguaggio si usavano modelli linguistici non molto ampi. Erano efficaci per compiti molto specifici come previsioni di eventi, individuazione di spam, traduzioni basilari. Ma nel 2017 arriva la svolta: un paper di Google Research introduce una nuova architettura di rete neurale chiamata “transformer”, in grado di generare modelli linguistici di qualità più elevata, impiegando meno tempo di addestramento. Inoltre questi transformer possono essere personalizzati facilmente per operare in domini specifici. Iniziano ad essere messi alla prova da aziende come Microsoft, Google, OpenAI e, così, nel 2020 si assiste al primo salto di specie: GPT-3 è il modello che funziona meglio per la creazione di testi.
Ma questi modelli sono difficili da far funzionare, richiedono architetture hardware complesse, GPU potenti per cui sono disponibili a poche aziende. Piano piano i costi iniziano a calare e, oggi, sono spuntati i primi software stand alone e web based che stanno aprendo le porte ai test di massa (vedi post sulla generazione di immagini da testo). DALL-E 2, rilasciato in beta a luglio, è usato da oltre 1,5 milioni di persone che producono più di 2 milioni di immagini al giorno. Midjourney, aperto prima al pubblico, ha più di 3 milioni di utenti.
La prossima fase sarà quella dell’integrazione di questi metodi di generazione all’interno di prodotti già ampiamente utilizzati dalle persone. Microsoft ha già annunciato che Dall-E si potrà usare dentro Bing e sono stati creati plugin per utilizzare Stable Diffusion nei prodotti Adobe.
I domini dell’IA Generativa
Vediamo quali sono i domini applicativi dell’intelligenza artificiale generativa, a che punto siamo e dove potremo arrivare.
- Testi: la creazione di testi da un input testuale è il campo, attualmente, più avanzato. I modelli in uso sono già in grado di generare ottimi testi brevi e di media lunghezza, che già vengono utilizzati in applicazioni pratiche di copywriting e di scrittura automatizzata di articoli di giornali. Nei prossimi anni arriveremo ad avere prime stesure migliori di quelle di professionista;
- Codice: oggi la scrittura di codice si ferma alla generazione di più linee, ma non va oltre. A breve si prevede di arrivare ad una maggiore accuratezza ed entro il 2030 di poter scrivere un testo e ottenere un prodotto software finale utilizzabile;
- Immagini: la generazione di immagini da un “prompt” testuale ha raggiunto degli ottimi livelli. Viene già usata per mostrare idee embrionali e per lavori finiti. Facile prevedere che nel giro di qualche anno sarà sempre più usata per ottenere contenuti già pronti per la commercializzazione;
- Audio: i modelli in grado di trasformare un testo in audio sono in circolazione da tempo. L’aspetto più difficile è la riproduzione di uno stile di conversazione vicino a quello umano;
- Video: la generazione di video e modelli tridimensionali da input di test è ancora in fase embrionale. I primi risultati decenti si potranno veder l’anno prossimo per poi procedere ad un miglioramento entro il 2025 e una personalizzazione più spinta nel 2030.
- Modelli 3D: stanno seguendo la stessa traiettoria dei video. Ancora siamo agli inizi. Ma tra il 2025 e il 2030 vedremo ambienti ricreati automaticamente da input umani (o anche da IA) che diventeranno parte dei mondi virtuali che visiteremo.

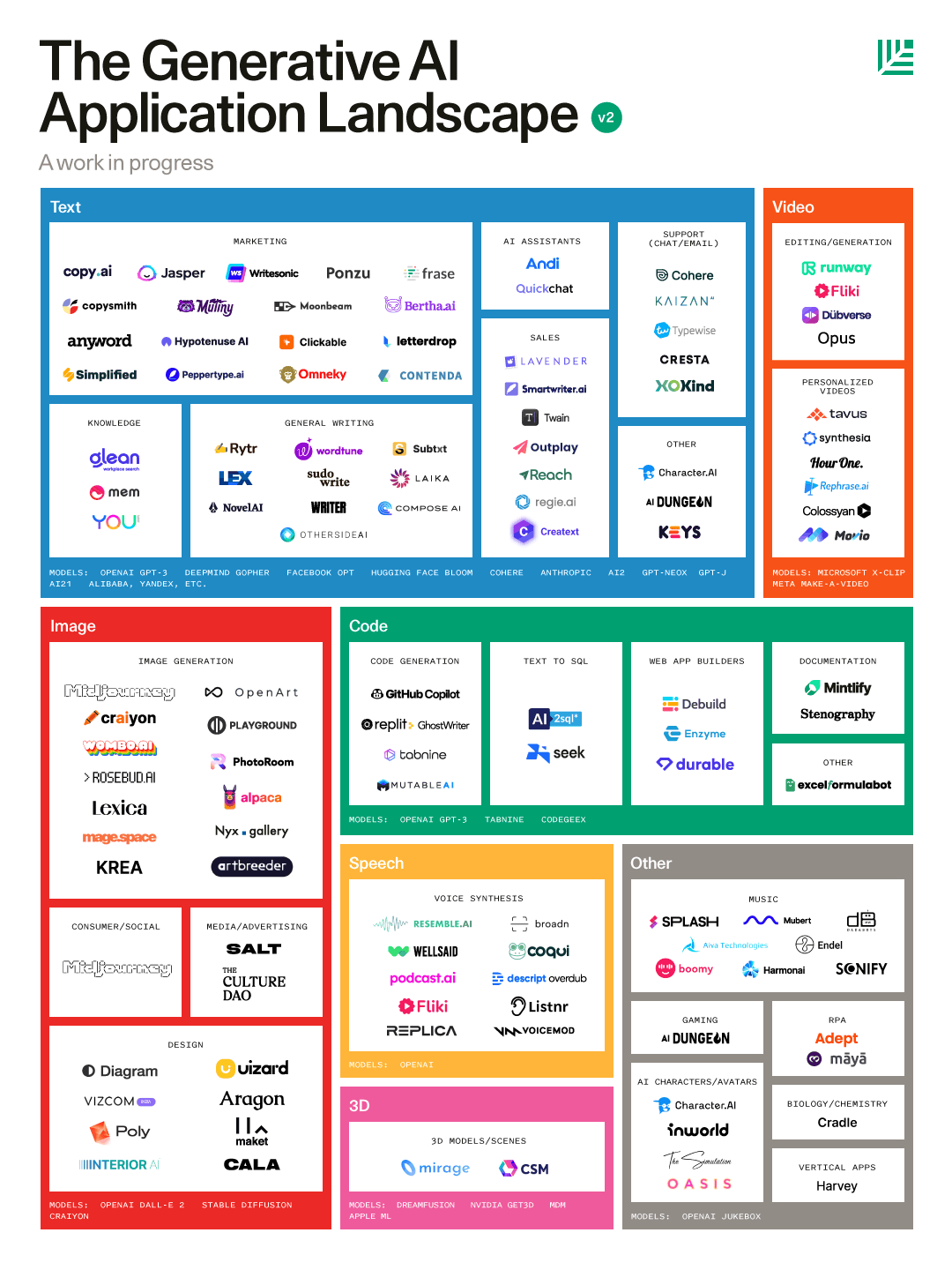
Le applicazioni esistenti
I modelli linguistici di grandi dimensioni (LLM) stanno portando alla nascita di prodotti che possono diventare dei “co-piloti” dei professionisti in vari campi. Va precisato che, al momento, funzionano bene con la lingua inglese, ma presto arriverà l’estensione ad altre lingue.
- Testi:
- Copywriting: i modelli linguistici “text to text” hanno dato vita a molti strumenti utilizzabili in ambito marketing e vendite, per la creazione rapida di testi per email commerciali, newsletter, social media post.
- Scrittura: software per assistere nella stesura corretta di testi. Per ora sono generalisti, ma si prevede una “verticalizzazione” degli stessi per coprire tematiche più specifiche come la scrittura di testi giuridici o copioni cinematografici;
- Assistenti intelligenti: in questo caso i modelli puntano a rendere le conversazioni via chat più credibili e utili;
- Knowledge: l’intelligenza artificiale qui viene usata per migliorare la ricerca di informazioni in azienda (Glean) o sul web (You) e ad auto organizzare lo spazio di lavoro (Mem),
- Video: strumenti che permettono di usare un testo per generare una sequenza di immagini o una particolare tipologia di montaggio video
- Immagini:
- Foto/Illustrazioni: i generatori di immagini da testo sono stati oggetto di uno specifico post;
- Design: strumenti che producono elementi di design come output, utili nella prototipazione di siti, prodotti digitali e fisici;
- Codice:
- Generazione di codice: strumenti che permettono di ottenere linee di codice da input testuali. Il più noto è GitHub Copilot che riesce a generare il 40% di codice nei progetti dove viene usato
- Text to SQL: tool di generazione di query SQL da input di testo
- Web App: in questo caso da un testo, ma senza scrivere codice, si riescono a creare delle applicazioni web o dei siti (Durable)
- Documentazione: tool per supportare la fase noiosa, ma fondamentale di scrittura della documentazione tecnica di accompagnamento al rilascio di software.
- Parlato: tool “text to speech” che permettono di trasformare un testo in un elemento audio, ad esempio una voce umana sintetica, appartenente ad una persona in carne ed ossa (clonazione) oppure creata ex novo. Possono essere utili nel “voice over” di video, nel far parlare avatar e personaggi di video giochi.
- Musica: strumenti che permettono di generare musica nuova da input, solitamente non testuali, ma predefiniti. Per esempio Mubert crea tracce sonore partendo dalla scelta di una tipologia di pezzo e di un genere musicale. Ma c’è anche chi sta realizzando tool che partono da note e arrivano alla realizzazione di un brano completo.
La mappa composta da Sequoia raccoglie anche nomi di aziende che ancora non hanno realizzato un prodotti solidi. Per esempio nel campo della generazione di mondi e oggetti tridimensionali da testo, siamo ancora in uno stadio sperimentale.