
Sono a Mountain View invitato da Google per assistere al loro evento più importante dell’anno: Google I/O 2026. Proverò ad appuntare sul blog le mie impressioni e le novità più importanti in una serie di post, rimandandovi a YouTube per demo approfondite.
Negli ultimi 12 mesi l’azienda ha dimostrato di essere in grado di sfornare prodotti e modelli di frontiera al pari dei competitor, ma la sua strategia di differenziazione è puntare ad un approccio integrato full-stack che parte dal design di hardware dedicato all’IA fino ai prodotti consumer ed enterprise.
Il filo conduttore di questa edizione è stato la cosiddetta “agentic era”, la fase agentiva dell’intelligenza artificiale generativa. L’IA che non si limita a rispondere alle nostre domande, ma agisce per nostro conto. In questa ottica vanno letti tutti gli annunci più importanti che provo a riassumere.
La famiglia Gemini 3.5: Flash e Lite
La nuova famiglia di modelli linguistici multimodali e agentivi si chiama Gemini 3.5. Le prime versioni ad essere immediatamente disponibili sono Gemini 3.5 Flash e Gemini 3.5 Lite. Gemini 3.5 Pro dovrebbe arrivare fra un mese.
Gemini 3.5 Flash è superiore a Gemini 3.1 Pro ed è 4 volte più veloce dei modelli di frontiera attuali. Sembra particolarmente efficace sulla scrittura di codice e attività agentive anche di lunga durata. Avendo anche un prezzo più contenuto rispetto ai modelli evoluti, è l’ideale per contenere i costi nelle aziende.
Gemini 3.5 Lite è la versione più leggera del modello pensata per dare risposte ancora più veloci.
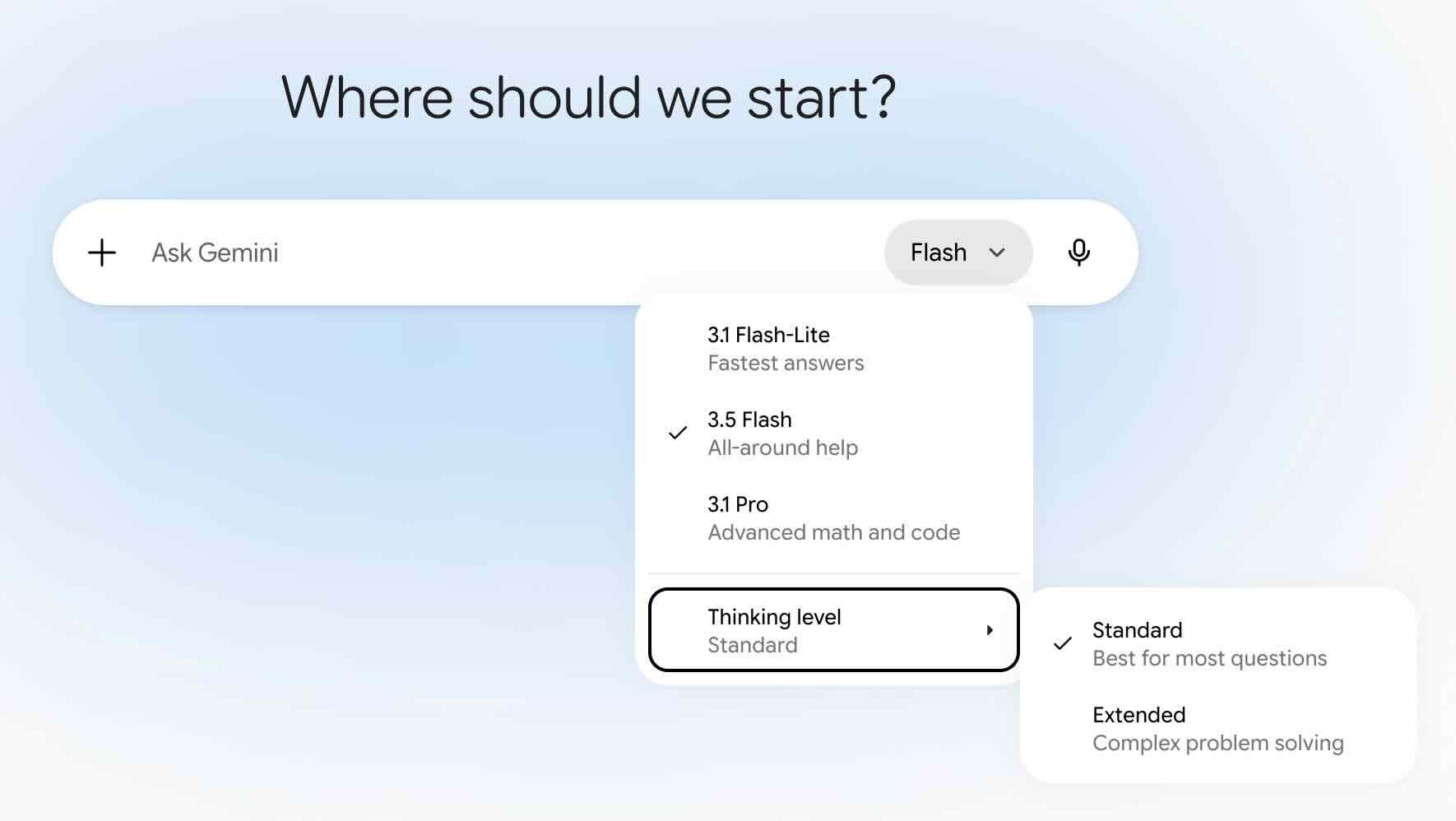
I nuovi modelli sono già utilizzabili dentro la nuova app di Gemini (anche se ci sono dei limiti di prompt utilizzabili ogni giorno a secondo dell’abbonamento che si possiede).
Un nuovo selettore posto nel prompt box permette di scegliere il modello da usare e il livello di sforzo computazionale. Al momento, scegliendo 3.5 Flash o Lite si può avere un “Thinking Level” Standard o Extended). Se si sceglie il modello 3.1 Pro si accede anche a Deep Think (ideale per il ragionamento in parallelo).
Gemini Omni
Anche quest’anno Google non trascura i modelli visivi. Se la scorsa volta aveva stupito tutti con Nano Banana, ora prova a fare il bis con una nuova famiglia di modelli generativi chiamata Gemini Omni (mio test).
La sua caratteristica principale è che può accettare qualsiasi fonte di input e restituire qualsiasi tipo di output. In questa prima fase gli input possono essere testi, immagini, video, audio (solo vocali, non musica) e l’output può essere solo video, ma arriveranno anche immagini e audio.
Il primo modello della famiglia ad essere distribuito è Gemini Omni Flash, già integrato nell’app Gemini (solo per gli utenti che hanno un abbonamento), in Google Flow e su YouTube Shorts. Le sue capacità sono:
- Editing video tramite linguaggio naturale: il sistema permette di modificare i filmati attraverso normali istruzioni testuali, con una gestione sequenziale delle modifiche. L’utente può chiedere di trasformare l’ambiente circostante, alterare l’azione in corso o inserire nuovi elementi e personaggi. Il modello promette di mantenere la coerenza dei personaggi e della scena anche dopo diverse modifiche consecutive.
- Consapevolezza fisica e culturale: a differenza dei modelli basati sulla semplice associazione visiva (pattern matching), Gemini Omni integra logica e conoscenze enciclopediche. Questo si traduce in una simulazione più realistica delle leggi della fisica (gravità, energia cinetica, dinamica dei fluidi) e nella capacità di generare video esplicativi complessi partendo da brevi input di testo, integrando nozioni storiche e scientifiche.
Gemini rinnovato, anche su desktop
Google ha ridisegnato da zero l’esperienza visiva di Gemini con un nuovo linguaggio di design chiamato Neural Expressive. L’interfaccia ora vanta animazioni fluide, colori vibranti, una nuova tipografia e feedback aptici.
Inoltre, Gemini non risponderà più solo con muri di testo, ma progetterà risposte dinamiche arricchite da immagini, timeline interattive, video narrati e grafiche.
Grande attenzione anche per la componente vocale in Gemini Live: finalmente si potrà passare da digitazione a conversazione vocale (e viceversa) senza interruzioni. In più, il chatbot non si interromperà se l’utente fa pause per pensare o usa intercalari.
La voce è anche al centro del prossimo aggiornamento dell’app desktop di Gemini per MacOS. Sarà possibile dare istruzioni parlando liberamente e senza preoccuparsi di eventuali errori.
Il nuovo Gemini Spark
La funzione più interessante che è stata introdotta si chiama Gemini Spark (mio test). Non è un chatbot reattivo, ma un agente AI personale attivo 24 ore su 24, 7 giorni su 7, che si abilita dall’applicazione Gemini.
Tecnicamente sfrutta il modello Gemini 3.5 a cui è stata aggiunta l'”imbracatura” di Antigravity (Antigravity harness). È profondamente integrato con la suite Google Workspace (Gmail, Docs, Slides, ecc.) per cui può essere usato per lavorare in background (in cloud) per attività anche lunghe.
L’agente può connettersi anche ad app esterne, sfruttando il protocollo MCP. Le prime integrazioni sono con Canva, OpenTable e Instacart. Nelle prossime settimane sarà in grado di inviare messaggi, scrivere email, creare sotto-agenti personalizzati e operare sul browser locale.
Gemini Spark sarà in beta dalla prossima settimana negli Stati Uniti per gli abbonati Google AI Ultra. Purtroppo non c’è ancora una data per l’arrivo in Italia. Spero presto perché, dalle demo che ho visto, l’integrazione profonda con l’ecosistema Google può rivelarsi molto utile per gli utenti che vogliono la potenza degli agenti senza voler perdere tempo in configurazioni cervellotiche.