
Hai mai provato a chiedere a quattro chatbot IA diversi di descrivere la tua azienda, un suo prodotto o il tuo personal brand? Otterrai, probabilmente, quattro ritratti diversi: alcuni ragionevolmente accurati, altri con errori fattuali e, magari, uno che ripesca un episodio che pensavi ormai sepolto.
Nessuno di questi ritratti è completamente inventato. Nascono tutti dalle stesse tracce, ma vengono lette, pesate e sintetizzate in modo diverso da ciascun modello, a seconda di chi sei e di cosa chiedi. La domanda interessante non è quale di queste sia “quella vera”. È cosa cambia per chi una marca la deve gestire.
Da messaggio a sintesi
Per decenni l’identità di marca è stata un monolite di significati: costruito dal management, veicolato attraverso canali controllabili. Negli anni del web e dei social è diventata un’identità negoziata con gli utenti, potenzialmente in grado di scalfire il monolite.
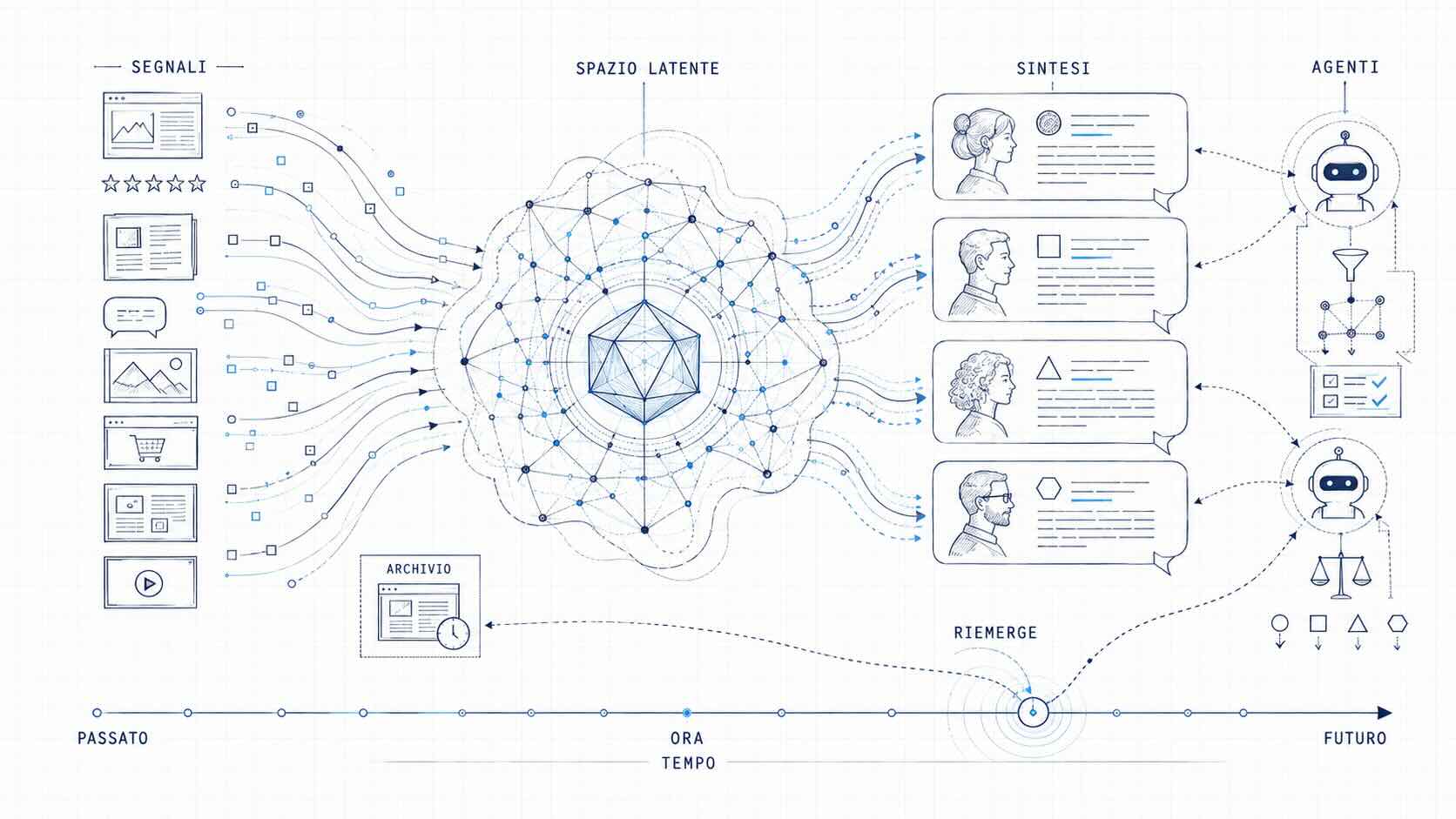
Oggi, nell’era della GenAI, sta diventando un’altra cosa ancora. Per dirlo serve prendere in prestito un’espressione tecnica: spazio latente. Dentro un modello linguistico di grandi dimensioni non c’è un archivio di frasi pronte, da pescare e restituire. C’è uno spazio matematico in cui ogni concetto è rappresentato come una posizione in mezzo a milioni di altri, e le risposte non vengono lette da un “cassetto”: vengono calcolate sul momento, attraversando quello spazio in base a ciò che chiedi. Lo stesso modello, sollecitato in modi leggermente diversi, percorre traiettorie diverse e produce risposte diverse. La risposta che cerchi non è scritta da nessuna parte finché non formuli la domanda.
L’identità di marca, oggi, si comporta esattamente così. Non vive più come un messaggio depositato da qualche parte e pronto all’uso. Esiste come pattern distribuito nelle tracce che l’azienda e le persone lasciano in giro (sito, recensioni, articoli, contenuti generati dagli utenti) e assume forma definita solo nel momento in cui un sistema intelligente viene interrogato su di essa. È latente nello stesso senso in cui lo è un concetto dentro il modello: c’è, ma come potenziale, non come elemento finito. E come per il modello, ogni risposta è leggermente diversa dalle altre, perché ogni sintesi dipende dal modello, dalla query, dal momento. Da qui il nome che ho scelto, marca latente.
Per usare un vocabolario più filosofico: è un’identità in potenza, che diventa atto solo nell’istante della sintesi. La distinzione è aristotelica e qui torna utile in senso letterale: la potenza è ciò che può essere ma non è ancora; l’atto è la sua realizzazione concreta. Una statua è in potenza nel blocco di marmo, diventa atto sotto lo scalpello. Allo stesso modo non esiste una marca con un’identità cristallizzata e univoca. Esiste un campo di significati possibili che, quando richiamati dall’utente (o da un agente IA), si manifestano: calcolati statisticamente sul momento.
È chiaro, allora, che pensare di avere il controllo sulla marca è un’illusione. Non da oggi: lo era anche prima. Ma la novità non è solo che l’IA rende quell’illusione visibile. È che ne introduce una variante inedita.
Nel mondo pre-GenAI il tempo dilavava le tracce: una crisi del 2022 sbiadiva, veniva archiviata, scivolava in fondo ai risultati di ricerca. Oggi quella stessa crisi può restare congelata nei pesi di un modello e riemergere intatta nel 2026, come se il tempo non fosse passato. Non è la vecchia perdita di controllo resa più evidente. È un meccanismo nuovo: la marca non sfugge più solo nello spazio, tra fonti che non governi, ma anche nel tempo, che non dilava più come faceva prima.
GEO, AEO, AIO: cosa cambia davvero
La tentazione, per chi guida un’azienda o un brand, è leggere tutto questo come una nuova disciplina. Già si parla di nuove forme di SEO come GEO (Generative Engine Optimization), AEO (Answer Engine Optimization) e AIO (AI Optimization come unione di GEO e AEO). Tanto che i manager hanno già iniziato a chiedere: “Come ci posizioniamo su ChatGPT?”.
Domanda legittima, che però spesso porta a risposte sbagliate: tattiche di breve respiro come keyword stuffing per LLM, recensioni gonfiate, prompt injection, che non risolvono il problema e a volte lo aggravano. Sia chiaro, non tutta la GEO è fuffa: presidiare fonti autorevoli, esporre dati strutturati, tenere coerenti i fatti che ti riguardano sono pratiche sensate, che peraltro coincidono in parte con la strategia che sto per descrivere. Il punto non è che la tattica sia sbagliata. È che da sola non basta, perché scambia un problema strategico per un problema di ottimizzazione.
Il problema è strategico, infatti. Se l’identità di marca esiste in potenza nelle tracce, allora la marca non si comunica più come un unicum: si progetta affinché emerga dalle tracce che lasciamo. Il messaggio resta uno dei segnali, il più controllabile, ma è solo uno. Il lavoro vero è disseminare nel mondo un insieme di segnali tale per cui un sintetizzatore, interrogato, restituisca una versione decente di te.
Per chi dovrebbe governare una marca al tempo dell’intelligenza artificiale significa quattro cose pratiche.
Le tracce non pesano tutte allo stesso modo. La gerarchia delle fonti non è più quella della SEO classica. Conta l’autorità della fonte, certo, ma contano almeno altrettanto due altri fattori.
Il primo è l’accessibilità tecnica. Un articolo eccellente di Repubblica dietro paywall pesa molto meno di un pezzo mediocre ma aperto, perché il crawler che alimenta l’addestramento fa fatica a leggerlo. Attenzione: il paywall riduce il peso, non lo azzera del tutto. I contenuti chiusi potrebbero rientrare comunque per altre vie, ad esempio dagli eventuali accordi di licenza tra editori e laboratori alle citazioni di terzi. Ma li penalizza in modo sistematico, e in una misura che chi pianifica le PR raramente considera.
Il secondo è la lingua. I corpora di addestramento sono massicciamente sbilanciati verso l’inglese. Il risultato è controintuitivo: a parità di accessibilità, un articolo aperto in inglese su una rivista di settore può pesare più di un pezzo lungo e ben scritto su una testata italiana. Molte aziende investono in PR nazionali in buona fede, convinte di costruire identità di marca, e ne costruiscono solo metà: quella visibile agli esseri umani, non quella leggibile dalle macchine.
Memoria e recupero sono due cose diverse. L’identità calcolata ha due strati che si comportano in modo differente.
Il primo è congelato nei pesi del modello al momento dell’addestramento. Ci entra al cutoff (il momento in cui l’azienda smette di addestrare il modello) e ci resta. Non per sempre, perché i modelli vengono riaddestrati dopo un certo numero di mesi, ma per un tempo imprevedibile. Pensa a un’azienda che ha cambiato nome, proprietà o posizionamento: per gli umani la transizione si è conclusa, per il modello la vecchia identità può sopravvivere mesi o anni nei suoi dati di addestramento.
Il secondo strato viene recuperato in tempo reale via ricerca e RAG (Retrieval Augmented Generation): più aggiornabile, ma dipendente da quali fonti il modello è configurato per consultare, e di questo, ad oggi, non sappiamo nulla. Qui basta che il primo risultato su un certo intento sia un forum pieno di critiche perché la sintesi ne risenta, anche se sui pesi la tua reputazione è solida. Gestire questi due strati separatamente, con logiche e orizzonti temporali diversi, è una competenza che quasi nessuno ha ancora sviluppato.
Le sintesi sono plurali. Non esiste la risposta dell’LLM sulla tua marca: ne esistono molte, una per ogni modello e una per ogni intento. “Scarpe da running per maratoneti”, “scarpe etiche”, “controversie sul marchio X” producono tre marche diverse con lo stesso nome. Monitorarle è un’attività che ha senso strutturare quanto il monitoraggio dei media tradizionali, con la differenza, non da poco, che qui i risultati cambiano ad ogni interrogazione. Quindi diffida dei tool magici di brand intelligence.
Stanno arrivando i lettori non umani. Nell’era agentiva, più vicina di quanto sembri, la marca non viene sintetizzata solo per un utente che legge. Viene letta e selezionata da agenti che decidono per conto dell’utente: comparano, filtrano, in alcuni casi acquistano. È il salto concettuale più importante, e quasi nessuno lo sta trattando.
Significa che, oltre a essere ben rappresentata, la marca deve essere leggibile e selezionabile da una macchina. Sono due requisiti diversi. Il primo lo conosciamo: è la reputazione, raccontata bene. Il secondo è nuovo. Un agente non si commuove per il tuo claim: confronta. Se i tuoi prezzi divergono tra il sito e i marketplace, se le specifiche di prodotto non coincidono da una fonte all’altra, se le informazioni che ti riguardano non sono esposte in forma strutturata e verificabile, l’agente non litiga con te: semplicemente ti scarta a favore di un concorrente più ordinato. La leggibilità per le macchine, fatta di dati strutturati, coerenza fattuale tra le fonti, claim verificabili, feed in formato machine-readable, smette di essere un dettaglio tecnico per gli sviluppatori e diventa una variabile competitiva. Per ora quasi del tutto ignorata.
Misurare la sintesi
Resta la domanda più scomoda: come si misura tutto questo? Non basta “chiedere a ChatGPT cosa pensa di noi” una volta e archiviare lo screenshot. La sintesi è plurale e mobile, e va trattata come tale.
In pratica vuol dire interrogare con regolarità più modelli, non uno solo, su un ventaglio di intenti che contano per il tuo business: il nome della marca, le categorie in cui competi, i temi sensibili, i confronti con i concorrenti. E vuol dire osservare non la singola risposta, ma la deriva delle risposte nel tempo: cosa compare e scompare, quali errori si sedimentano, quando un episodio che credevi chiuso torna a galla. È un monitoraggio più simile a una rilevazione longitudinale che a un controllo puntuale. Nessuno ti consegna una metrica pulita; il lavoro è costruirsi una serie storica e imparare a leggerla.
Iniziare a sperimentare
L’identità di marca latente è una responsabilità manageriale che pochi stanno ancora trattando come tale. È, a ben vedere, un nuovo gap di consapevolezza: la marca produce continuamente versioni di sé che chi la governa non vede, non misura e nemmeno sa di dover gestire. E non gestirla è una forma di abdicazione a monte: si delega alle macchine la sintesi della propria identità senza nemmeno accorgersene.
Capire quali tracce esistono, quali pesano, quali vanno costruite o ricostruite, come misurare la sintesi che ne emerge: è un lavoro ancora poco definito e poco codificato. Ma è un lavoro, e ognuno di noi farebbe bene a iniziare a sperimentare per poterlo fare al meglio.