Due anni fa rimasi a bocca aperta nel vedere come un software, GPT-3, riusciva a generare testi di senso compiuto, indistinguibili da quelli di un umano, partendo da un minimo input iniziale. Oggi, siamo di fronte ad un nuovo salto tecnologico perché è diventato possibile far creare immagini ad una macchina, semplicemente fornendole delle minime indicazioni testuali. Il passaggio da testo ad immagine è ancora più strabiliante perché rende più evidente la “magia” della creazione e ci interroga sull’origine della creatività, sul significato di arte e di autore.
Temi estremamente stimolanti che lascio ad una prossima trattazione. Per ora mi interessa presentarvi questi nuovi software, senza entrare in dettagli tecnici, ma dandovi dei riferimenti per poterli provare autonomamente.
Possiamo dividerli in due categorie: quelli meno sofisticati, ma facilmente accessibili (Dream, StarryAI, Craiyon) e quelli più sofisticati, ma ad accesso limitato (DALL-E 2, Imagen, Parti, Midjourney).
Come funzionano i generatori di immagini
I generatori di immagini sono basati su reti generative avversarie o GAN (Generative Adversarial Networks). Si tratta di architetture nelle quali due reti neurali si sfidano in una sorta di gioco a somma zero. La rete detta Generatore, partendo da numeri casuali, ha il compito di elaborare immagini realistiche, provando ad ingannare il Discriminatore. La rete Discriminatore viene addestrata a riconoscere immagini preesistenti, attraverso l’analisi di milioni di esempi etichettati appropriatamente, con l’obiettivo di capire se quelle prodotte dal Generatore sono reali o artificiali. Pian piano, di tentativo in tentativo, il Generatore impara a produrre immagini sintetiche che sembrano create da un umano.
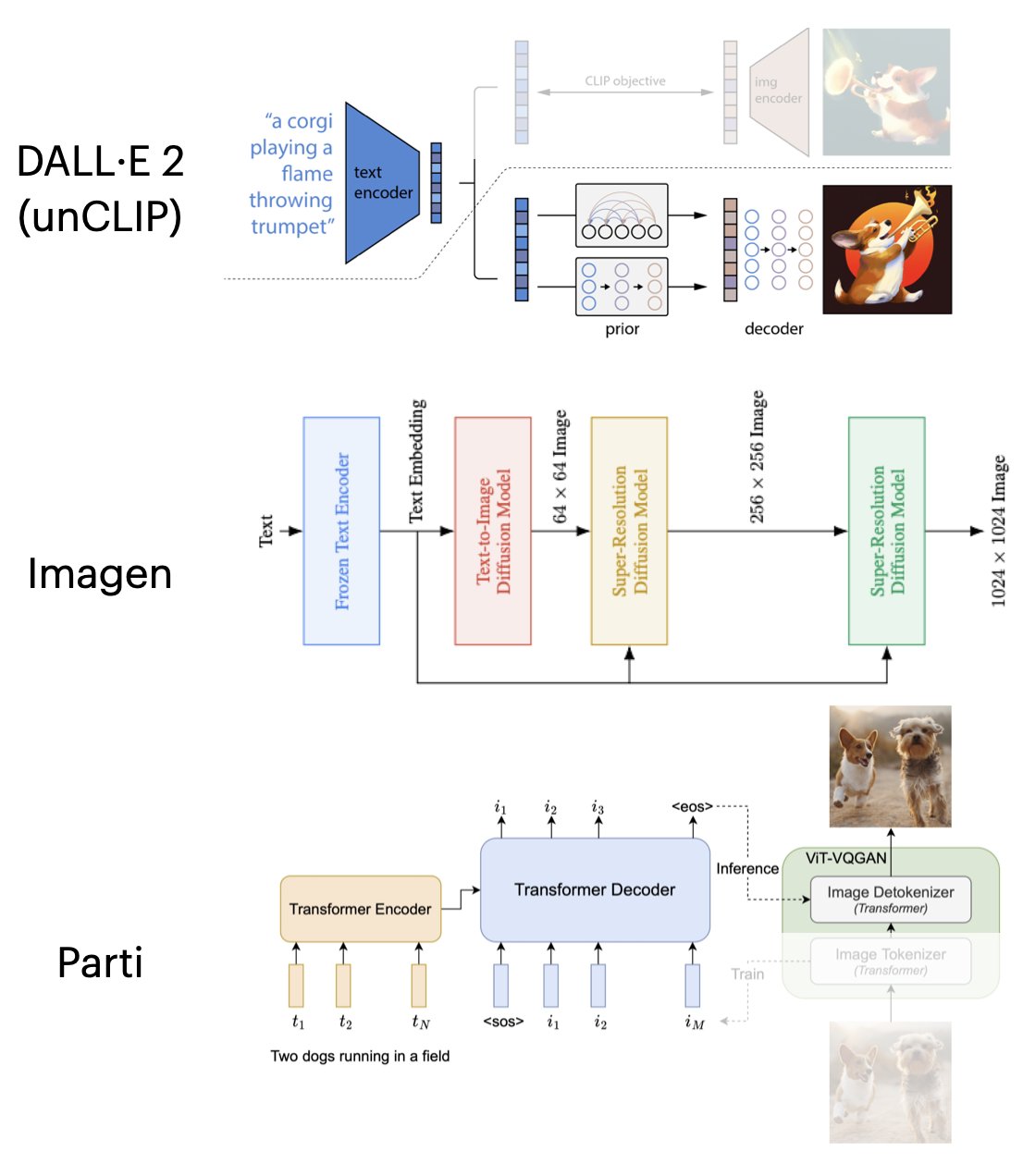
I sistemi più evoluti di “text to image”, come quelli di OpenAI e Imagen di Google, usano dei “diffusion model”. Entrambi partono da un modello in grado di comprendere delle frasi complesse, non semplici parole chiave.
Nel sistema di OpenAI queste frasi vengono passate a dei calcolatori che usano un modello, detto “prior”, che ha il compito di generare “CLIP image embeddings” ossia di “farsi un’idea” di quelle parole (come succede a noi umani quando ci chiedono di disegnare una una spiaggia con degli ombrelloni e delle barche all’orizzonte). Poi queste “CLIP image embeddings” vengono passate ad un altra rete che sulla base di un “Decoder Diffusion model” (unCLIP) inizia a disegnare quell’idea per passi successivi (vedi video in basso).
Anche Imagen di Google usa un “diffusion model”, mentre il nuovo Parti usa un “autoregressive model” per trasformare le parole in immagini con un codificatore di testo che attinge a 20 miliardi di parametri (dettagli tecnici).
Le app per trasformare un testo in immagine
In un precedente post avevo scritto di come gli algoritmi di Intelligenza Artificiale siano ormai incorporati in molti software per la creatività al fine di permettere all’utente di ottenere risultati prima irraggiungibili. Ora, invece, vi accompagno nell’esplorazione di quei servizi progettati col solo obiettivo di trasformare un testo, vago o dettagliato, in un’immagine.
Dream
La prima applicazione ad essere arrivata sul mercato è stata Dream di Wombo. Andando sul sito o scaricando l’app è possibile generare gratuitamente immagini da un imput testuale, in pochi secondi. Basta inserire delle parole chiave, non frasi complesse, e scegliere uno stile pittorico da una lista di oltre venti modelli. Il software restituisce un’immagine che si può scaricare, acquistare come poster o “coniare” come NFT.
Negli ultimi mesi è stata aggiunta la possibilità di dare come input un’immagine da caricare, che la macchina reinterpreterà secondo lo stile scelto.
Dream è una soluzione semplice, gratuita, ma non avanzata. Un grande limite riguarda l’aspetto esclusivamente verticale dell’output.

Starryai
Starryai è molto simile a Dream. Si può usare dall’app o dal sito web, con un modello freemium. Per iniziare bisogna scegliere tra due modalità di creazione: una più astratta (Altair che usa un modello VQGAN-CLIP) e una più realistica (detta Orion, che usa un modello CLIP-Guided Diffusion). Dopo di che si accede al pannello dove immettere il testo di input e scegliere lo stile di riproduzione tra una lista predefinita. Anche qui si può partire da un’immagine preesistente e scegliere anche tra alcune dimensioni predefinite per l’output finale.
Il servizio è gratuito ma per un numero limitato di creazioni. Si hanno 5 crediti che non corrispondono a 5 output, perché i compiti più complessi valgono più di un credito.

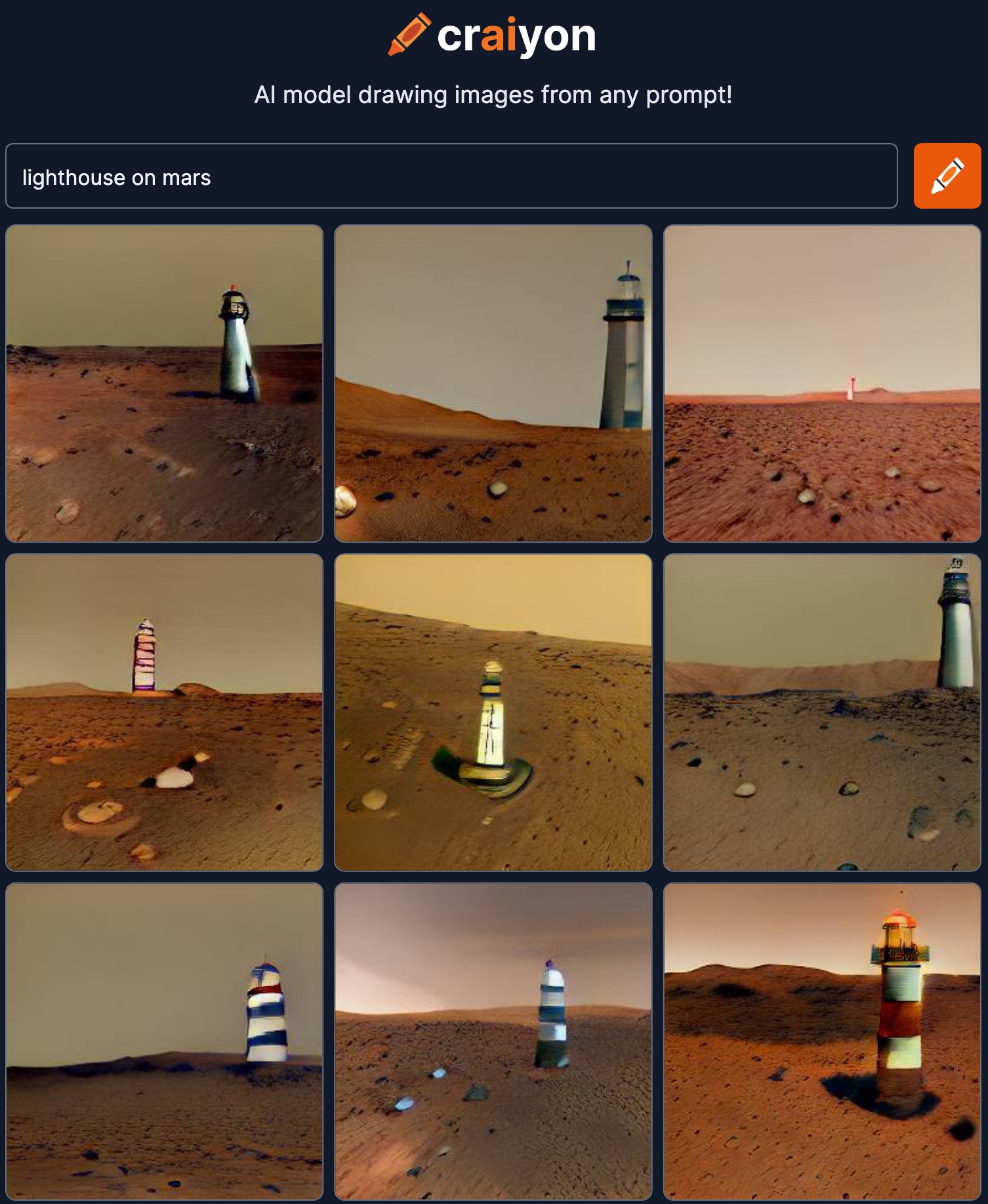
Craiyon
Craiyon è un progetto nato da qualche mese da due sviluppatori che inizialmente lo avevano denominato DALL-E Mini. Usa un modello VQGAN. Si può usare gratuitamente, ma solo via web, attraverso un’interfaccia spartana che permette di inserire il testo desiderato. L’output consiste in nove immagini scaricabili, ma di bassa risoluzione.
Funziona abbastanza bene con testi semplici, ma se provate a creare immagini che prevedono l’interazione tra più oggetti/soggetti, il risultato risulterà pasticciato.
DALL-E
DALL-E, un gioco di parole tra Salvador Dalí e il personaggio della Pixar WALL-E, è un progetto di ricerca di OpenAI. La prima versione è del gennaio 2021 ma era limitata alla creazione di immagini di piccola dimensione (256×256 pixel). DALL-E 2, rilasciato in beta privata ad Aprile del 2022, oltre a poter generare immagini più grandi (1.024×1.024 pixel) ha anche funzioni più avanzate.
Innanzitutto è in grado di comprendere la relazione tra gli oggetti per cui da un input del tipo “un cane shiba inu che indossa un berretto ed un girocollo nero” riesce a riprodurre perfettamente la scena. Ciò, ovviamente, apre le porte a creazioni di fantasia che possono risultare molto realistiche (questo è uno dei motivi per i quali il software non è stato reso disponibile a tutti).
Inoltre, questa nuova versione usa una tecnica chiamata “inpainting” che permette all’utente di rimpiazzare uno specifico elemento di un’immagine precedentemente generata. Infine, è anche molto efficace nella creazione di varianti alternative di una immagine.
Non ho avuto ancora modo di mettere le mani su DALL-E 2 (c’è una waiting list), ma da quanto vedo riesce a produrre immagini molto più fotografiche di altri strumenti.

Imagen e Parti
Imagen e Parti sono due progetti di ricerca del Brain Team di Google Research che corrispondono a due diversi modelli di generazione di immagini da un testo iniziale. Non sono ancora aperti al pubblico, ma da quello che si legge sul sito Imagen sarebbe più preciso di DALL-E nella creazione di immagini verosimili.
Due problemi riscontrati in questi modelli riguardano il fatto che non riescono a riprodurre un numero specifico di oggetti, es. dieci mele, né sanno collocarli correttamente nello spazio (es. una mela a destra e una pera a sinistra).

Midjourney
Midjourney ora è pubblicamente disponibile è ancora in fase di beta privata, accessibile solo su invito (se ne vuoi uno lascia un commento indicando il tuo account Discord e proverò ad aiutarti). Per utilizzarlo bisogna avere un account su Discord perché la generazione degli output avviene attraverso un bot. Dopo l’iscrizione, infatti, si entra in una stanza del server di Midjourney e può iniziare ad usare il comando di base /imagine seguito dalla descrizione in inglese di quello che si vuole realizzare. Inoltre, si possono aggiungere anche dei parametri come le dimensioni (qui una video guida per iniziare).
Nel giro di pochi secondi il bot risponde con quattro immagini numerate (1 e 2 corrispondono a quelle in alto, 3 e 4 a quelle in basso). Ognuna di queste può essere portata ad una maggiore risoluzione (upscale) o modificata (variation), premendo, rispettivamente, i tasti U e V (es. se si vuole ottenere una variazione dell’immagine in alto a sinistra bisogna premere il tasto V1). Dopo il primo Upscale, che si ferma ad una risoluzione di 1024×1024, viene data la possibilità di un ulteriore miglioramento col tasto “Upscale to Max”.
Un vantaggio di Midjourney è proprio la risoluzione che può arrivare fino a 1792×1024 pixel. Un difetto è che non riesce ad utilizzare un’immagine come input (cosa che DALL-E può fare).
Dopo la fase di trial, il servizio si può acquistare spendendo 10$ o 30$ a seconda delle funzioni che si vogliono ottenere e dell’uso che se ne vuole fare.
Sto facendo parecchi esperimenti che raccoglierò in questo thread su Twitter e devo dire che spesso il software mi sorprende con le sue soluzioni inaspettate. Però per ottenere risultati eccelsi bisogna trovare le parole giuste e iterare più volte le operazioni di generazione.

Stable Diffusion
Stable Diffusion è un altro modello diffusivo realizzato da Stability AI, CompVis LMU e Runway. La prima release pubblica è datata agosto 2022. Il suo codice è stato reso disponibile a tutti per cui può essere istallato sul proprio computer, un approccio diverso dagli altri servizi visti. Chi non vuole sobbarcarsi questo onere può usare un’interfaccia via browser chiamata DreamStudio. Al primo accesso si ottengono dei crediti per generare una serie di immagini gratuitamente, poi si deve pagare per averne di più.

Intelligenza Artificiale per potenziare la creatività
In questo momento i programmi di generazione di immagini più sofisticati sono in fase di sperimentazione. Prima di essere rilasciati a tutti ne vanno studiati i rischi di utilizzo come la produzione di contenuti violenti o falsi che possono mettere in cattiva luce determinate persone o categorie e la generazione di output che possono riflettere i pregiudizi e gli stereotipi contenuti nei modelli linguistici di grandi dimensioni.
Prima o poi questi software diventeranno di dominio pubblico, si moltiplicheranno ed evolveranno (probabilmente entro cinque anni li vedremo applicati ai video, qui una panoramica delle applicazioni possibili). Forse daranno un duro colpo al settore delle foto stock perché diventerà semplice generare immagini standardizzate, ma offriranno anche un grosso aiuto ad artisti, creativi e marketer.
Sì, perché questi programmi sono degli ottimi generatori di idee a basso prezzo che potrebbero aiutare a superare i blocchi creativi. I marketer e i creator ne potrebbero beneficiare anche per la produzione di contenuti per blog post, siti, pubblicità, presentazioni o anche per produrre mockup e suggestioni iniziali per un brief ad un’agenzia.
Insomma, questi strumenti basati sull’Intelligenza Artificiale non distruggeranno la creatività, ma spalancheranno le porte della percezione dei più creativi e amplificheranno le possibilità di creazione dei meno dotati.





Vincenzo, anche io sto sperimentando un po’.
Segnalo anche Disco Distribution, non so se hai dato un’occhiata.
Ti invio il mio username Discord perche’ mi piacerebbe ottenere un accesso a Midjourney.
Surycata#3010
Ciao, piacerebbe anche a me ricevere un invito per MidJourney.
Barabba Marlin#3822
Anch’io vorrei l’invito per Midjourney su discord
Surycata#3010
è libero ormai
ciao Vincenzo. se avanza un invito a Midjourney, butriga#7705
grazie mille!
pierofioretti#3367
Ciao, mi piacerebbe provare… LNRD#5825
ciao, hanno aperto a tutti quindi basta seguire il link
Ciao Mi piacerebbe avere un invito per Midjourney, ma pur essendomi iscritto a Discord (nome utente: Fabrizio Mirone), non riesco ad ottenerlo. Puoi aiutarmi?
ciao Fabrizio,
se vai su Midjourney.com puoi fare “join the beta” ed entrare liberamente. Hanno tolto le restrizioni.
Ciao, ti ringrazio per la risposta. L’ho fatto, mi sono iscritto passando da Join the beta ma una volta entrato nella mia dashboard personale non riesco comunque ad accedere al pannello che mi permette di generare immagini.
in basso a sinistra c’è l’icona di Discord, se la premi troverai l’opzione “go to Discord” per accedere al pannello
Ciao
Il mio account discord è Mornar#1164
ciao, ora non c’è più bisogno di invito, basta registrarsi
Ciao! Per favore se ti avanza un invito rp#3989
ciao, ora non c’è più bisogno di invito, basta registrarsi
Ciao! Complimenti per l articolo chiaro e conciso. Per favore se ti avanza un invito rp#3989
Grazie mille
ciao, ora non c’è più bisogno di invito, basta registrarsi
Ciao, se possibile, ti chiederei di ricevere un aiutino per avere anche io l’invito per MidJourney.
FoxDrill#6630
ciao, ora non c’è più bisogno di invito, basta registrarsi al sito
ciao, vorrei sperimentare Midjourney. Mi manderesti l’invito, per favore?
Grazie mille.
Il mio nickname è giada.negri-gn82
non c’è più bisogno, basta andare sul sito e registrarsi
Ciao, anche io sono molto curioso di provare Midjourney, potresti mandarmi un invito?
JabryHell#7046
Grazie mille
non c’è più bisogno, basta andare sul sito e registrarsi
Ciao, è sempre possibile ricevere un invito su midjourney? Grazie
pas#7504
non c’è bisogno d’invito, ora è aperto a tutti
Ciao! Bellissimo articolo, complimenti! Per favore potresti aiutarmi per il canale discord?
Ecco il mio discord:
Vincent234#8087
Devi semplicemente andare qui https://www.midjourney.com/app/ e poi registrarti usando Discord (quindi devi prima avere un account discord)
Ciao non è molto facile capire cosa devi fare ma è bello
ciao Elena, sul mio canale YouTube trovi qualche tutorial https://www.youtube.com/@VincenzoCosenza